The data warehouse has various backend tools for refreshing the data. These tools use the ETL functions. Let us discuss each of these:
- Extraction: Data Extraction collects data from multiple data sources heterogeneous, external data sources.
- Transformation: The data from different sources is in source format. It is transformed into a format compatible with the warehouse structure in this step.
- Loading: In this step, the data is sorted, loaded, summarized and consolidated to check the integrity of data and create partitions.
Data Cleaning: Data is cleaned after extraction to find out any error and correct them and then sent for transformation.
Data refreshing is done to update the warehouse from the data sources.
The ETL steps improve the data quality and thus provide a good data warehouse management tools.

What is Metadata Repository?
Metadata explains data about data. It describes the components of a data warehouse. Metadata is created for defining data in the data warehouse. Metadata also stores the source of data, timestamp of data extracted from sources, added data for missing values and integrated data. Metadata repository resides in the warehouse along with raw data and summarized data of the Data warehouse system.
A metadata repository stores:
- Data warehouse structure: The data warehouse structure, schema, dimensions, and hierarchies are stored. Also, it stores the data definitions, locations, and contents on subsets of the data warehouse.
- Operational metadata: The transformation, migrations applied to data, the statistics of DW, any errors and audits are stored. It also stores the data status such as active or archived.
- System Performance: The metadata repository stores the measures which improve the performance of the DW including data access and retrieval methods.
- Mapped data: The information related to databases, contents of the database, data partitions, data extraction rules, and user security information is stored.
- Metadata related to business: The terms and conditions of business, data ownership, etc. are stored.
- Summarization Algorithms: The summarization and aggregation algorithms, queries and reports applied to the data is stored in the metadata repository.
Function of Metadata:
Functions of the metadata are given below:
- Metadata helps in locating the contents of the database,
- It acts as a guide to find out the mapping of data from the operational environment to a warehouse environment.
- It also tells about the various summarization and aggregation algorithms applied to the data in DW.
- It gives information on the data extraction and transformation process from data source to the data warehouse.
What is Data Cube?
Data warehouses are multidimensional data models. The data can be viewed in the form of data cubes.
The data cube is a type of data model where data can be viewed in multidimensional space. A data cube is defined by dimensions and facts.
A data cube in a data warehouse is an “n-dimensional structure”. With multiple dimensions such as location, product, quarter and supplier, an in a data warehouse, a cuboid can be created using subsets of dimensions. These cuboids form a lattice representing a different level of summarization. This lattice of cuboids is called a data cube. The “lattice of cuboids” with 4 dimensions is given below:

The above diagram shows apex cuboid, it shows all the dimensions, that is the highest level of summarization. The facts summarized for all dimensions are denoted by the apex. The 4-D base cuboid holds the lowest level of summarization. The 3D cuboid represents a summary of 3 dimensions: time, item, location based on supplier, time, item, a supplier based on location and item, location and supplier based on time
In 2D representation, data is represented in the form of rows and columns. For example, a table representing product and month of the year for city: Delhi.
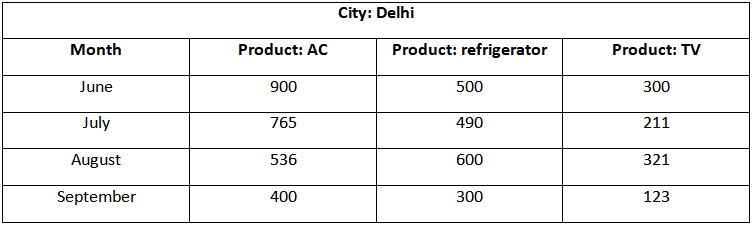
Now if we want to analyze the above data which respect to a different location in Delhi such as Delhi, Jaipur, Chandigarh, area. etc. along with month and product. Then we would need a 3D representation like:
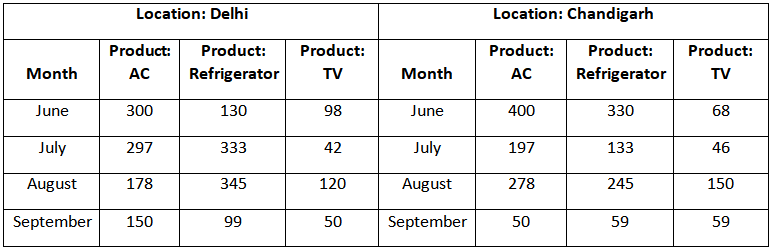
Similarly, we can create a 3D model for other locations Jaipur, Punjab, and Haryana. This 3 D representation is showing 2D tables series. This 3D data can also be shown in the form of a 3D data cube as below.
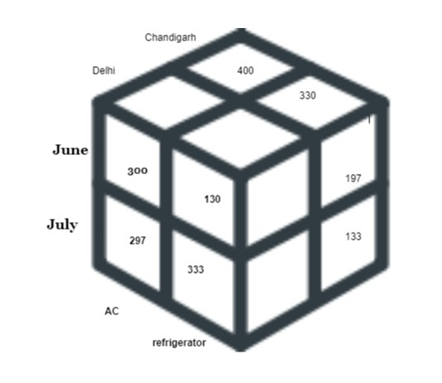
What is Dimension?
The dimension represents the entities with respect to which the records are stored. Dimensions are represented in the form of tables and are used to track records, for example, sales record or purchasing record. A dimension “product” can have attributes,”product_id”, “product_name”, “product_price”.
|
|
|
|
|
|
|
|
|
|
What is Facts?
Fact represents numeric measures. Facts are used to find out the relationship between dimensions. The fact table contains the keys of the dimension tables related to the fact and the fact measures. For example, a fact table can contain, “product_id” and fact measure “units_sold”.
|
|
|
|
|
|
|
|
Concept of Hierarchies:
Concept hierarchy is a mapping of low-level concepts to high-level concepts. For example mapping of the location to the city, city to state, state to the country as shown in the figure below:
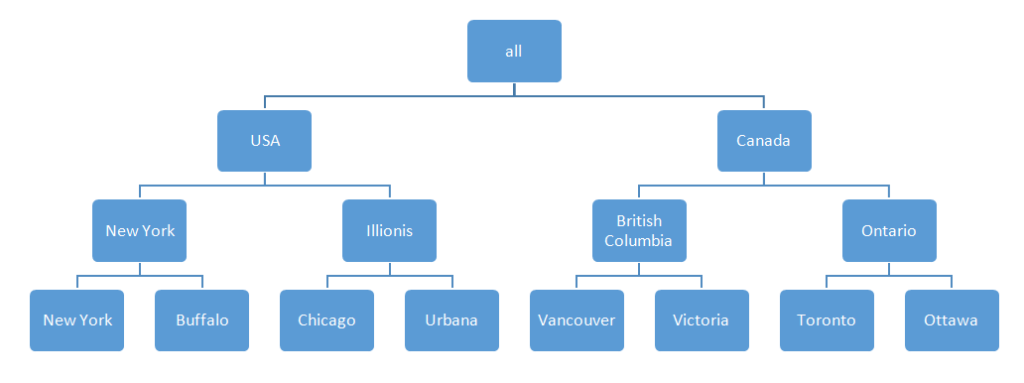
The concept hierarchies are implicitly defined in the database. The attributes of a dimension may be partially or fully organized in a hierarchy. Example of fully organized dimension attributes are: “street < city < province or state < country” and partially organized dimension attributes: “street < city < province or state < country”. This full or partial order is called the schema hierarchy.
Type of Data Storage in Data Warehouse:
The data warehouse contains:
Metadata repository: It stores data about data warehouse.
Disc Storage: It stores the current data
Tertiary Storage: This type of storage stores the older data
Physical Storage: This type of storage stores the light summarized data storage and high summarized data.
Next tutorial, we can going to discuss the Data warehouse Models: Star Schema and Snowflake schema.

⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!
