
Hadoop Pig is a high-level programming language which is used to analyze the large data sets. It was an outcome of development effort at Yahoo!
Unlike MapReduce framework, where the programs need to be translated into a series of Map and Reduce stages, in Apache Pig first of all it is not a programming model that data analysts are acquainted to, but it is an abstraction language called Pig which was built on top of Hadoop in order to bridge this gap. Due to the introduction of abstraction, the Apache Pig developers spend more time on analyzing bulk data sets instead of resolving Map-Reduce programs. The name ‘Apache Pig’ is given considering the fact that the way that Pig eats lots of food and here in this case, it works upon any kind of data.
Hadoop Pig Architecture


Hadoop Pig consists of the following two components.
- Pig Latin, which is a language.
- A runtime environment which is required to run PigLatin programs.
A PigLatin program contains a series of operations or conversions which are applied to the input set of data in order to produce the desired output. These conversions describe a data flow which is interpreted into an executable representation with the help of Pig execution environment. Beneath, the results of these conversions are nothing but the series of MapReduce jobs that a programmer is uninformed of. Therefore, we can say that Pig allows the programmer to focus much on data analysis rather than the nature of execution.
Pig Latin is a comparatively comprehensive language that uses familiar keywords from the data processing e.g., Group, Join, and Filter.


Execution modes of Pig
Pig has the following two execution modes.
- Local mode: In the local mode, Pig runs on a single JVM and makes the best use of local file system. The local mode is suitable only for the data analysis of small data sets using Pig.
- Map Reduce mode: In the map reduce mode, the queries are written in Pig Latin language which are translated into MapReduce jobs and these jobs are executed on a Hadoop cluster. Such cluster can be pseudo or fully distributed cluster. MapReduce mode in the fully distributed Hadoop cluster is capable to run Pig on large data sets.
Download and Installation of Apache Pig
The following steps need to be followed to download and install Apache Pig.
Step1: Login to the PC with the privileged credentials in order to install Apache Pig software on your system.
su hduser Password
Privileged Access
Step 2: Download and install ‘Apache Pig software from the below given link.

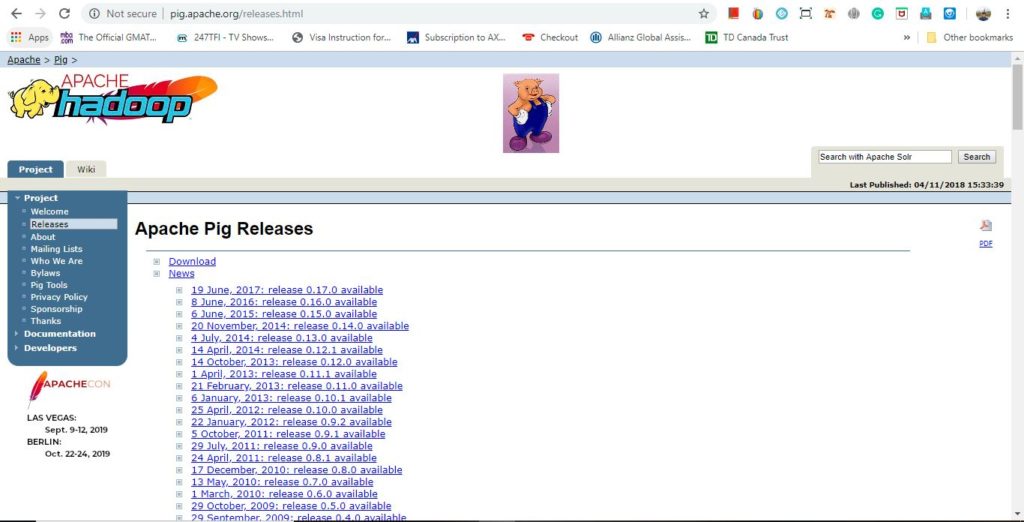
Click on the download link, which will take you to a new web page as shown below. Click the link to download the latest stable build of Apache Pig software on your system.

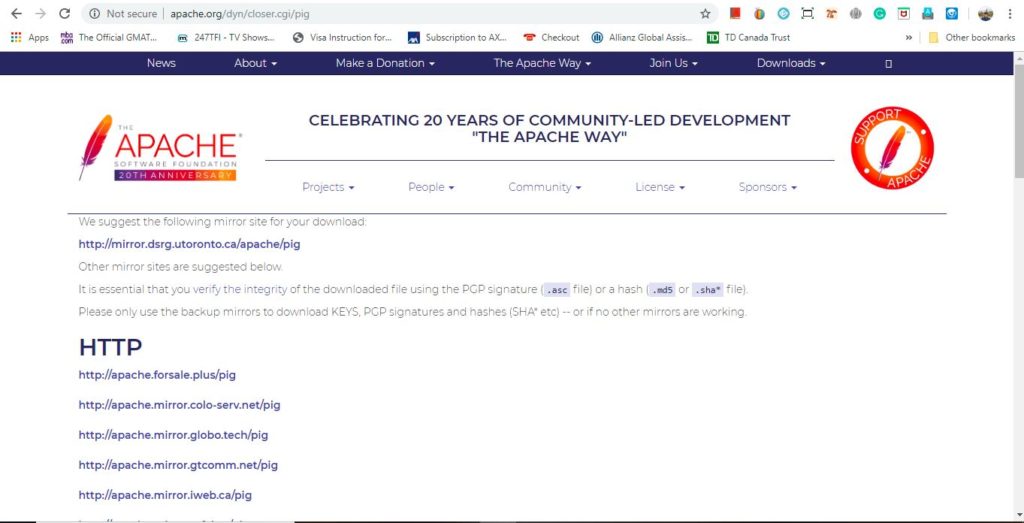

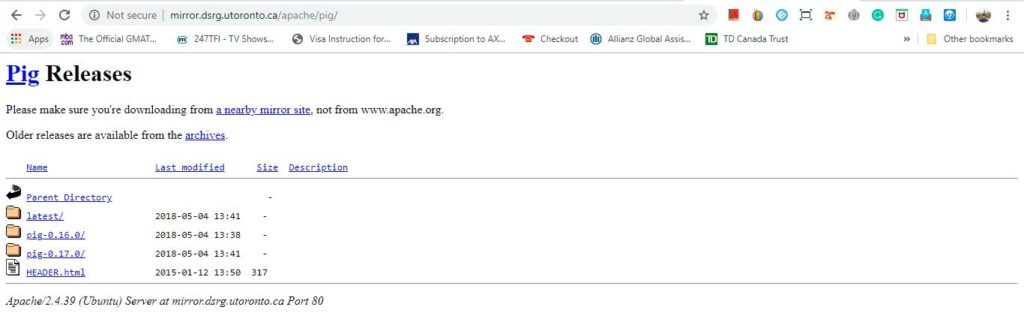
The latest version of the downloaded file is pig-0.17.0.tar.gz. This should be noted that tar.gz file should be downloaded (not src.tar.gz).
Step 3: Once a download of pig-0.17.0.tar.gz has completed, navigate to the directory containing the downloaded tar file. Next, move the tar to the location where Apache Pig need to set up. In this case, we will move to /usr/local
cd /usr/local
Location
Step 4: Next, extract the contents by using the following command in order to untar the file.
sudo tar -xvf pig-0.17.0.tar.gz
UNTAR the tar file for Apache Flumez
The above command will create a new directory with the name as ‘pig-0.17.0’ and it will serve as an installation directory.
Step 5: Next, modify ~/.bashrc in order to add Pig related environment variables. Open ~/.bashrc file in any text editor and do the following modifications. Post modification execute ~/.bashrc command to source this environment configuration.
export PIG_HOME=<Installation directory of Pig> export PATH=$PIG_HOME/bin:$HADOOP_HOME/bin:$PATH
Environment variables setup
Step 6: Next, we need to recompile Apache PIG in order to support Hadoop 2.2.0 with the help of following commands. The execution of these commands will require internet as they involve the installation of multiple components from Internet. This step may take 20 minutes of time.
cd $PIG_HOME sudo apt-get install ant sudo ant clean jar-all -Dhadoopversion=23
Apache PIG recompilation
Step 7: After successful installation of Apache Pig followed by the environment variable setup and recompilation of Hadoop 2.2.0, we are all set to test the Pig installation using the command.
pig -help
Apache PIG installation test
Conclusion
In this chapter, we discussed about Apache Pig architecture and the basic steps to download, install, and set up Apache Pig software on our system.
>>> Checkout Big Data Tutorial List
⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!